Data structure
Quote from osric on August 4, 2018, 12:39Is there a doc that explains the data structure? When I import a count sheet into Excel I’m having a hard time figuring out what it all means.
All I want from the data set is the same info I see onscreen in the app - I don’t need all of the additional detail. Is there a simple way to extract just a summary of counts by mode?
Is there a doc that explains the data structure? When I import a count sheet into Excel I’m having a hard time figuring out what it all means.
All I want from the data set is the same info I see onscreen in the app - I don’t need all of the additional detail. Is there a simple way to extract just a summary of counts by mode?
Quote from CounterPoint Admin on August 4, 2018, 17:56Hi,
I can explain further on the data structure for the csv.
Remember there are currently 4 count types (Easy, Regular, Carpool, Bicycle Gender) and 11 conditions.
The columns that relate to an Easy Count are:
- walk_generic
- bike_generic
- vehicle_personal
- vehicle_oversized
The columns that relate to a Carpool Count are:
- onePerson
- twoPerson
- threePerson
- fourPlusPerson
The columns that relate to a Bicycle Gender Count are
- gender_m (male)
- gender_f (female)
- gender_o (other/unsure)
The columns that relate to a Regular Count are: (These can be collapsed down into “Easy Count” columns if needed)
- bike_adult
- bike_child
- bike_baby (in-app bike passenger)
- bike_cargo
- bike_child_trailer
- walk_adult
- walk_child
- walk_stroller
- walk_disability
- walk_skateboard
- walk_visually_impaired
- walk_physically_impaired (walk)
- vehicle_car
- vehicle_moto
- vehicle_semi
- vehicle_transit (oversized)
The columns that relate to Conditions are:
- sunny
- cloudy
- raining
- snowing
- night
- construction
- special_event
- road_closed
- icy_roads
- wet_roads
- muddy_roads
The other columns:
- counterpoint_id: this is the unique identifier of the counterpoint the dataset came from. In one download there will only be one counterpoint_id
- count_session_id: This is the unqie identifier of each counting seasion that happenned at the counterpoint in question.
- count_id: This is the unique id of the minute during the cross section. We originally decided to group a count_session’s data into minute sections. Each minute section is a row in the csv, that has a parent count_session and the count_session has a parent of a counterpoint.
- user_id: Represents the unique id of the user that conducted the counterpoint that conducted this count. You can use this to group or segment your data how you like.
- team_id: Represents the unique identifier of a team that conducted this count. This helps if you are only interested in seeing data done by your team at this counterpoint.
- name: The name of the counterpoint
- intersection: The nearest intersection of the counterpoint
- description: The description or “comments” of the counterpoint
- lat: The latitude part of the coordinate of the counterpoint
- lng: The longitude part of the coordinate of the counterpoint
- start_datetime: The start time of the counting session
- end_datetime: The end time of the counting session
- elapsed_time: The difference between end_datetime and start_datetime in seconds
- timezone: The timezone of the counterpoint. This is needed if you want to compare counts across multiple timezones in their local time. Say you want to compare counts across Canada that all happen at 5:00pm local. Use the start_datetime and start_endtime rather than utc_start_datetime and utc_end_datetime.
- timestamp: The minute by minute timestamp of the count. All the timestamps associated to one unique count_session (count_session_id) should all be 1 minute apart.
Further, I will write this up in a better form of documentation, as well as adding these descriptions to the second row of the csv export.
Hi,
I can explain further on the data structure for the csv.
Remember there are currently 4 count types (Easy, Regular, Carpool, Bicycle Gender) and 11 conditions.
The columns that relate to an Easy Count are:
- walk_generic
- bike_generic
- vehicle_personal
- vehicle_oversized
The columns that relate to a Carpool Count are:
- onePerson
- twoPerson
- threePerson
- fourPlusPerson
The columns that relate to a Bicycle Gender Count are
- gender_m (male)
- gender_f (female)
- gender_o (other/unsure)
The columns that relate to a Regular Count are: (These can be collapsed down into “Easy Count” columns if needed)
- bike_adult
- bike_child
- bike_baby (in-app bike passenger)
- bike_cargo
- bike_child_trailer
- walk_adult
- walk_child
- walk_stroller
- walk_disability
- walk_skateboard
- walk_visually_impaired
- walk_physically_impaired (walk)
- vehicle_car
- vehicle_moto
- vehicle_semi
- vehicle_transit (oversized)
The columns that relate to Conditions are:
- sunny
- cloudy
- raining
- snowing
- night
- construction
- special_event
- road_closed
- icy_roads
- wet_roads
- muddy_roads
The other columns:
- counterpoint_id: this is the unique identifier of the counterpoint the dataset came from. In one download there will only be one counterpoint_id
- count_session_id: This is the unqie identifier of each counting seasion that happenned at the counterpoint in question.
- count_id: This is the unique id of the minute during the cross section. We originally decided to group a count_session’s data into minute sections. Each minute section is a row in the csv, that has a parent count_session and the count_session has a parent of a counterpoint.
- user_id: Represents the unique id of the user that conducted the counterpoint that conducted this count. You can use this to group or segment your data how you like.
- team_id: Represents the unique identifier of a team that conducted this count. This helps if you are only interested in seeing data done by your team at this counterpoint.
- name: The name of the counterpoint
- intersection: The nearest intersection of the counterpoint
- description: The description or “comments” of the counterpoint
- lat: The latitude part of the coordinate of the counterpoint
- lng: The longitude part of the coordinate of the counterpoint
- start_datetime: The start time of the counting session
- end_datetime: The end time of the counting session
- elapsed_time: The difference between end_datetime and start_datetime in seconds
- timezone: The timezone of the counterpoint. This is needed if you want to compare counts across multiple timezones in their local time. Say you want to compare counts across Canada that all happen at 5:00pm local. Use the start_datetime and start_endtime rather than utc_start_datetime and utc_end_datetime.
- timestamp: The minute by minute timestamp of the count. All the timestamps associated to one unique count_session (count_session_id) should all be 1 minute apart.
Further, I will write this up in a better form of documentation, as well as adding these descriptions to the second row of the csv export.
Quote from CounterPoint Admin on August 4, 2018, 23:00As an aside, I see you are looking for more condensed stats. I have opened up two links that the app’s use to generate their stats.
1. This gives you the accumulated stats for a given counterpoint.
- https://counterpointapp.herokuapp.com/api/v2/counterpoints/<INSERT_COUNTERPOINT_ID>/stats?outputFormat=csv
2.This gives you a list of accumulated stats for each count session for a given counterpoint
- https://counterpointapp.herokuapp.com/api/v2/counterpoints/<INSERT_COUNTERPOINT_ID>/counthistory/stats?outputFormat=csv
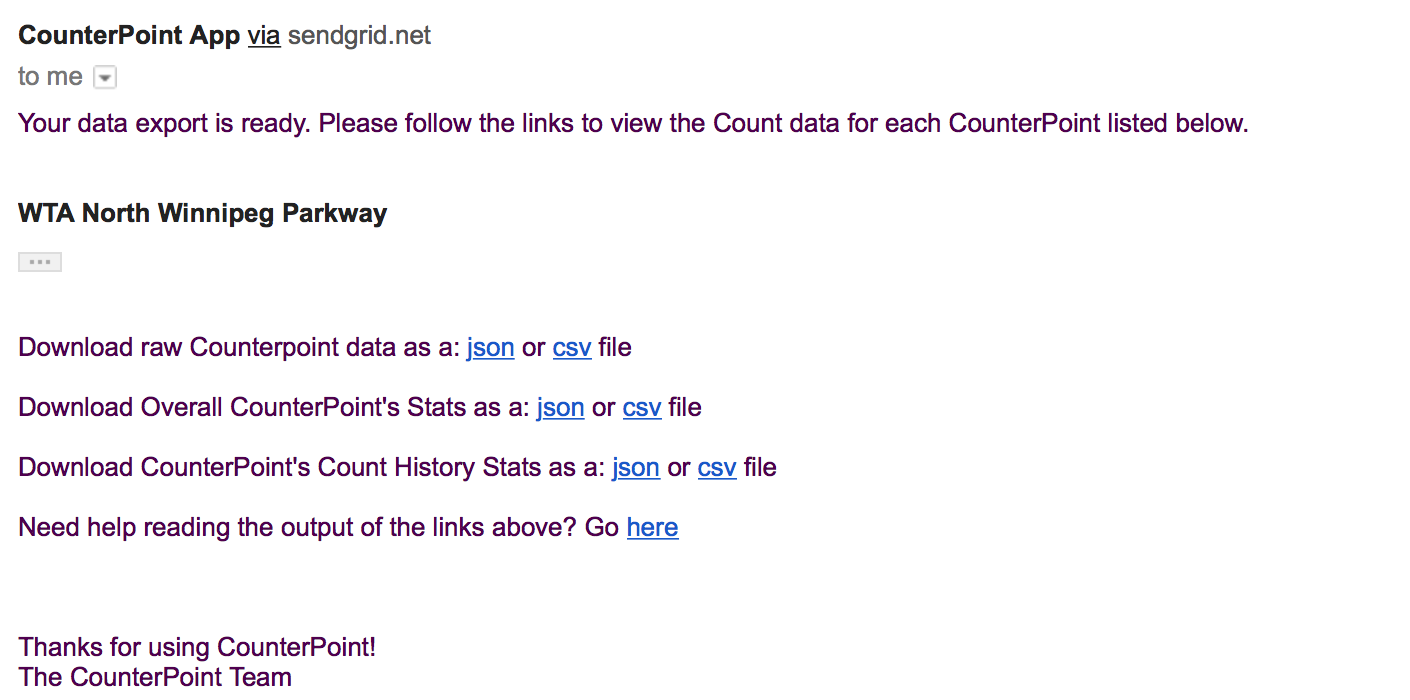
I have also added these two links in the body of the data export email that gets sent out on Android and iOS. The email also replaces <INSERT_COUNTERPOINT_ID> above with the appropriate counterpoint “ID” when you export. I had plans of adding these links to the data export email sooner then later anyways. Attached is a screenshot of the new email format shown. Try downloading data from a counterpoint again and you will see the changes to the email.
As an aside, I see you are looking for more condensed stats. I have opened up two links that the app’s use to generate their stats.
1. This gives you the accumulated stats for a given counterpoint.
2.This gives you a list of accumulated stats for each count session for a given counterpoint
I have also added these two links in the body of the data export email that gets sent out on Android and iOS. The email also replaces <INSERT_COUNTERPOINT_ID> above with the appropriate counterpoint “ID” when you export. I had plans of adding these links to the data export email sooner then later anyways. Attached is a screenshot of the new email format shown. Try downloading data from a counterpoint again and you will see the changes to the email.
Uploaded files:
Quote from CounterPoint Admin on July 9, 2020, 16:53@osric - Check out the beta version of our Data Explorer that was released recently.
- https://counterpointapp.org > Click the "Data Explorer" item in the menu.
@osric - Check out the beta version of our Data Explorer that was released recently.
- https://counterpointapp.org > Click the "Data Explorer" item in the menu.
Uploaded files: